



Module -1
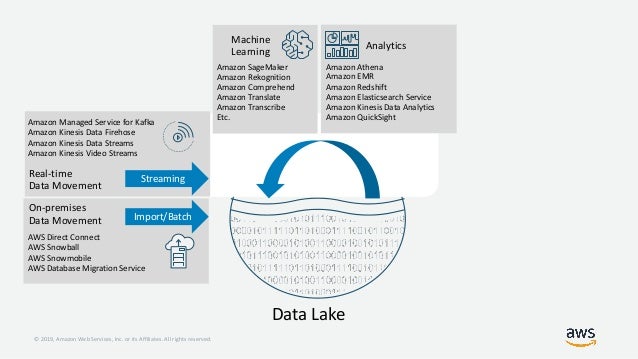
1-Data Lake
A data lake is a large and centralized repository that stores vast raw, unprocessed, and structured or unstructured data. Unlike traditional data warehouses that store structured data in predefined schemas, data lakes can handle diverse data types, including text, images, videos, log files, sensor data, and more. The data in a data lake is typically stored in its native format, without the need for transformation or normalization.
Let's take an example
Imagine a large storage room in your school called the "Data Lake." This room is like a giant container where all kinds of information are stored in their original forms. Instead of neatly arranging books on shelves like in a library (which represents traditional data warehousing), the Data Lake allows you to throw everything into the room without worrying about the organization.
Here's how it works:
Raw Data Collection: In the Data Lake, you can collect all sorts of data from different sources, just like you collect notes, textbooks, magazines, and even random papers in the room.
Data Variety: The Data Lake accepts different types of data, such as text, images, audio, videos, and more. This variety represents the various types of information you gather, like your academic notes, pictures from school events, recorded lectures, and even interesting articles or videos you find on the internet.
No Sorting Required: Unlike a library where books need to be categorized and arranged, the Data Lake doesn't require you to organize the data beforehand. You can put everything in the room as it is.
Data Exploration: Whenever you need to find specific information, you can dive into the Data Lake and explore its contents. You can search for a particular topic, keyword, or date to find the relevant data. Similarly, when you want to study a specific subject, you can search for related notes and resources.
Data Processing (Optional): If you want to analyze or combine some of the data, you can take it out of the Data Lake and process it separately. For example, you might sort and arrange your academic notes by subject or create a summary of important points.
Data Management: To keep the Data Lake clean and organized, you might use labels, tags, or folders for grouping related data. Similarly, data management techniques like data cataloging and data governance help ensure the quality and security of the data.
In summary, a data lake is like a massive room where you can collect and store different types of information without worrying about arranging them up front. It allows for easy exploration and analysis when needed. Just like the Data Lake simplifies data storage, real data lakes in the tech world serve as large, versatile storage repositories for organizations to store and process vast amounts of raw data from various sources.
2-Key characteristics of a data lake:
Scalability: Data lakes can scale horizontally, accommodating massive amounts of data from various sources, making them suitable for big data applications.
Flexibility: Data lakes can store both structured and unstructured data, allowing organizations to analyze and process diverse data types without upfront schema definitions.
Centralization: Data lakes provide a centralized and cost-effective storage solution for large-scale data, promoting data sharing and collaboration within an organization.
Data Catalog: To enable efficient data discovery and analysis, data lakes may have a data catalog or metadata management system that helps users understand the available data assets.
Data Governance: Implementing proper data governance measures is crucial to ensure data quality, security, and compliance within the data lake environment.
Data Processing: While data lakes store raw data, they often integrate with data processing frameworks like Apache Spark, Apache Hive, or Apache Flink to perform data transformations, analytics, and reporting.
3-Database vs Data Warehouse vs Data Lake | What is the Difference?
1. Database:

Definition: A database is a structured collection of data organized in a specific way to facilitate efficient data storage, retrieval, and manipulation. It uses a predefined schema that defines the data tables, their relationships, and the data types.
Characteristics:
Data in databases is typically organized in rows and columns within tables.
It follows the ACID (Atomicity, Consistency, Isolation, Durability) properties to ensure data integrity and reliability.
Databases are designed for transactional processing, where individual operations are completed successfully or not at all.
2. Data Warehouse:
Definition: A data warehouse is a large, centralized repository that consolidates data from various sources, including databases, applications, and external systems. It is used for analytical processing and business intelligence purposes.
Characteristics:
Data warehouses use a schema-on-write approach, where data is structured and transformed before being stored in the warehouse.
The data is optimized for querying and reporting, allowing complex analytical operations on large datasets.
Data warehouses typically support historical data and provide a long-term view of an organization's data.
OLAP Analysis-
OLAP stands for Online Analytical Processing. It is a category of software tools and technologies used for interactive and multidimensional analysis of data. OLAP analysis allows users to gain insights from large volumes of data by providing a flexible and intuitive way to explore and analyze information from multiple dimensions.
Analysis Process-
OLAP analysis is a data exploration technique using a multidimensional data structure called a "cube." This cube organizes data into dimensions (attributes like time, geography, and product) and measures (numeric values like sales revenue). The data is pre-aggregated at various levels of granularity to make queries faster.
Users can interact with the cube through OLAP tools, performing drill-down (going into more detailed data) and roll-up (summarizing data to higher levels). Slicing and dicing allow users to select specific dimensions to view subsets of data based on certain criteria.
OLAP queries are processed by the OLAP engine, leveraging the pre-aggregated data and specialized algorithms for quick responses. The analysis helps users gain insights, perform complex calculations, and make data-driven decisions efficiently.
ETL Process
ETL stands for Extract, Transform, Load. It is a process used to extract data from various sources, transform it to fit the desired target data model or structure, and then load it into the target database, data warehouse, or data lake. The ETL process is a fundamental part of data integration and data preparation for analysis and reporting.

3. Data Lake:

Definition: A data lake is a massive and flexible storage repository that holds vast amounts of raw, unprocessed, and diverse data, including structured, semi-structured, and unstructured data.
Characteristics:
Data lakes use a schema-on-read approach, which means data is stored in its raw form and is structured when it's ready for analysis.
It accepts data from various sources without requiring upfront schema definitions, making it suitable for big data and exploratory analytics.
Data lakes support data of various formats, such as text, images, videos, log files, and more, making them highly versatile.
Differences:
Database:
Data Structure: Databases store structured data in predefined schemas with a specific data model, such as relational databases (tables with rows and columns).
Data Processing: Databases support transactional operations, focusing on real-time data processing, CRUD operations (Create, Read, Update, Delete), and maintaining data consistency.
Data Source: Databases are typically used to store and manage data generated by applications and systems within an organization.
Data Integration: Databases often involve complex ETL (Extract, Transform, Load) processes to extract data from various sources, transform it to fit the database schema, and load it into the database.
Data Usage: Databases provide efficient storage and retrieval of data, enabling transactional operations and supporting real-time applications.
Data Warehouse:
Data Structure: Data warehouses store structured data from various sources, following a predefined schema known as a star or snowflake schema, designed for efficient data analysis.
Data Processing: Data warehouses focus on processing large volumes of data and performing complex queries for analytical purposes, including aggregations, data mining, and business intelligence.
Data Source: Data warehouses integrate data from multiple operational databases, external sources, and other data systems, transforming and consolidating it into a unified and consistent format.
Data Integration: Data warehouses involve data integration processes that extract, transform, and load data from various sources, ensuring data quality and consistency.
Data Usage: Data warehouses support decision-making processes, providing historical and aggregated data for complex analysis, reporting, and business intelligence.
Data Lake:
Data Structure: Data lakes store both structured and unstructured data in its raw, native format, without predefined schemas. It maintains the original structure of the data.
Data Processing: Data lakes facilitate data exploration, allowing for on-the-fly processing, ad-hoc queries, and a variety of data analyses, including machine learning and data mining.
Data Source: Data lakes accept data from diverse sources, such as IoT devices, log files, social media, and external systems, without the need for extensive data transformation or integration upfront.
Data Integration: Data lakes support a "store first, process later" approach, enabling data to be ingested in its raw form. Data integration and transformation occur at the time of analysis, providing flexibility and agility.
Data Usage: Data lakes cater to exploratory and advanced analytics, encouraging data scientists, analysts, and researchers to explore and derive insights from large volumes and varieties of data.
4-Fragmented AI Data Stack
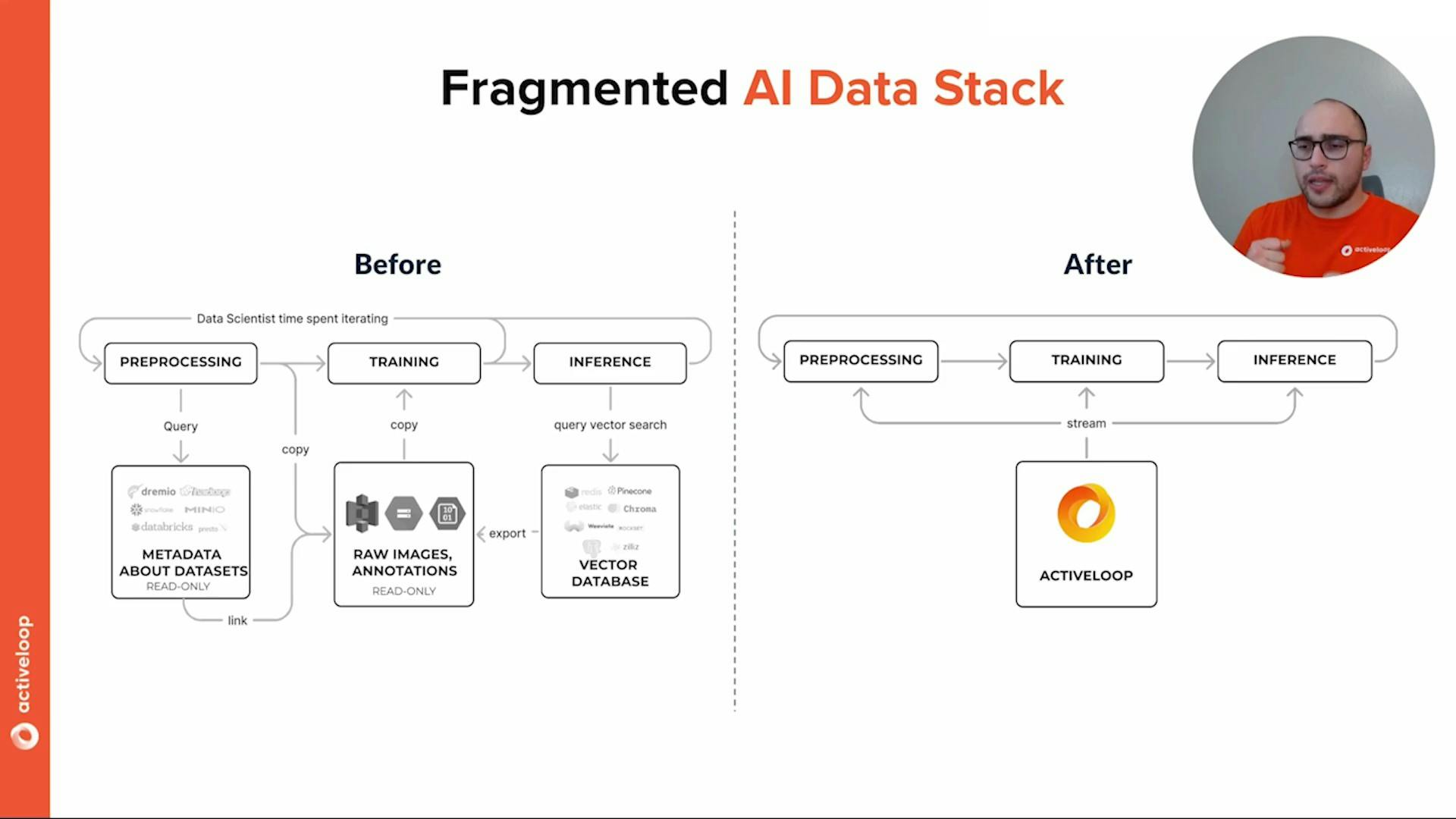
Imagine the AI data stack is like organizing a big puzzle.
Puzzle Pieces Everywhere: In a fragmented AI data stack, the pieces of the puzzle are scattered all over the place. Each piece represents a part of the data needed for AI.
Different Puzzle Types: The pieces come in different shapes and sizes, and they don't fit together well because they belong to different types of puzzles.
Difficulty in Making the Picture: Trying to complete the puzzle becomes challenging because you have to search for pieces in different places and figure out how they connect.
Messy and Incomplete Picture: As a result, the final picture (the insights you want from AI) looks messy and incomplete because the pieces don't fit together perfectly.
Solution - Organize the Pieces: To make things easier, you need to organize all the puzzle pieces in one place and sort them according to the puzzle type.
Fit the Pieces Together: With all the pieces organized, you can now easily fit them together to create a beautiful and meaningful picture.
The Outcome: By organizing the puzzle pieces (the data) properly, you can now get clear and useful insights from the AI, leading to better decisions and understanding.
5-ActiveLoop
" Database for AI "
Store Vectors, Images, Texts, Videos, etc. Use with LLMs/LangChain. Store, query, version, & visualize any AI data. Stream data in real time to PyTorch/TensorFlow.
Activeloop is creating the database for AI to enable data scientists to build a solid data foundation for their machine and deep learning workflows. Join the data-centric AI movement.
6- WHAT'S DEEP LAKE?
Optimizing Data Lakes for Deep Learning
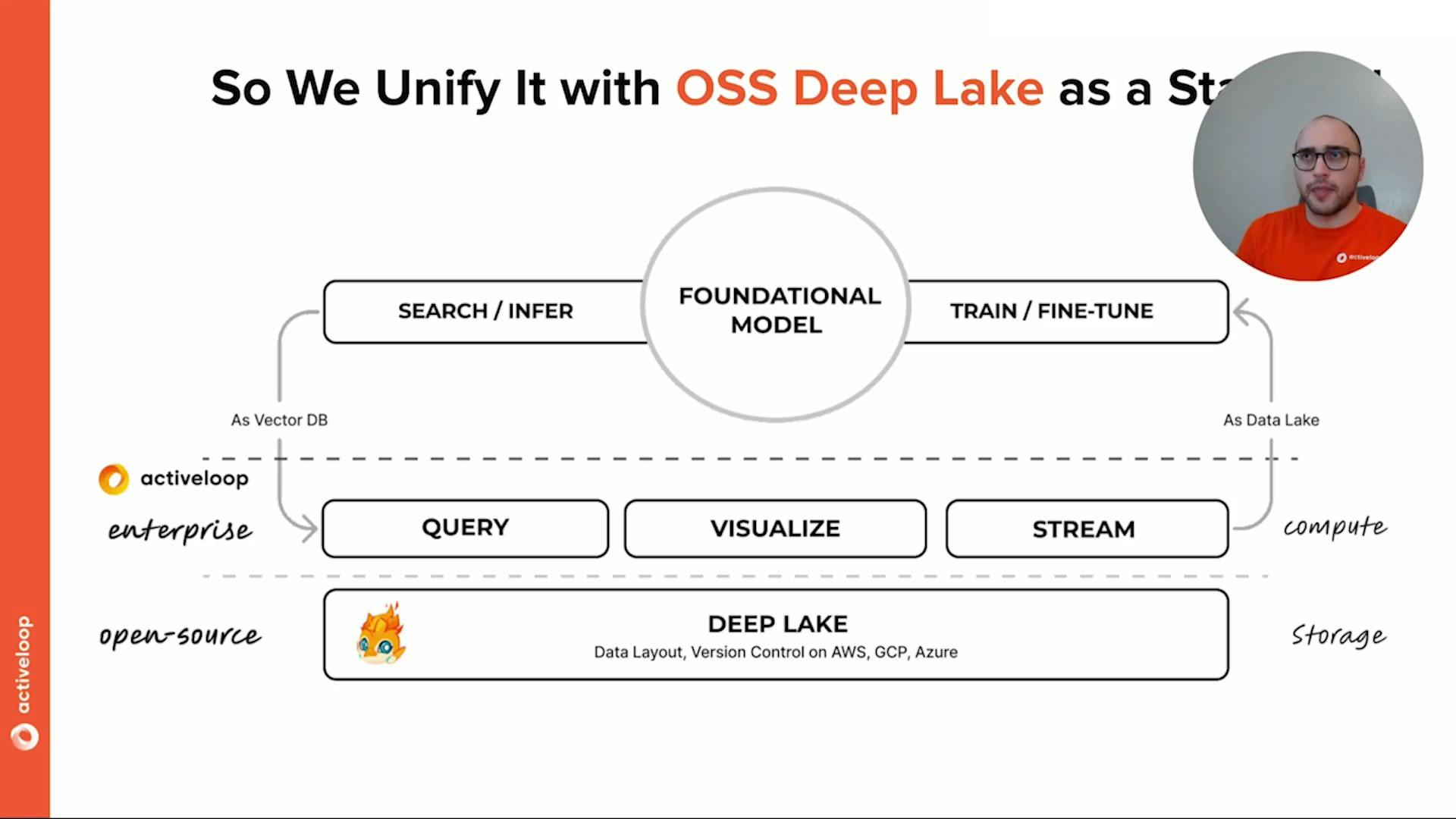
Deep Lake is a versatile tool described in docs.activeloop.ai that serves as both a Vector Store and a Data Lake for various purposes, including deep learning.
Vector Store: Deep Lake acts as a Vector Store, allowing you to store embeddings and their associated metadata, like text, JSONs, images, audio, video, and more. You can store this data locally, on your cloud, or on Deep Lake's storage. The Vector Store enables hybrid search operations, combining embeddings and their attributes. Deep Lake also offers the ability to build LLM Apps (Language, Layout, and Metadata Apps) with LangChain and LlamaIndex integrations. Additionally, computations can be performed on the client side, their Managed Tensor Database, or a serverless deployment in your VPC.
Data Lake for Deep Learning: Deep Lake can also be utilized as a Data Lake specifically for deep learning purposes. It allows you to store various types of data such as images, audio, videos, text, and their metadata (annotations) in a data format optimized for deep learning. Similar to the Vector Store functionality, you can save this data locally, on your cloud, or on Activeloop storage. With Deep Lake, you can train PyTorch and TensorFlow models rapidly by streaming data without needing complex boilerplate code. Additionally, it provides features like version control, dataset queries, and support for distributed workloads using a straightforward Python API.
7- Features of Deep Lake
Multi-modal
Fine-tuning
Deployment
Visualization
Version control
Open-source