

Day-1:
Cloud Basics
Revolutionizing Computing with Speed, Flexibility, and Innovation
Imagine you're a student working on a group project. Instead of relying on individual laptops or USB drives, you utilize cloud computing. The cloud acts as a virtual backpack, securely storing all your project materials. Accessible from any device with an internet connection eliminates the risk of losing files due to device failures or misplacements.
With cloud computing, collaboration becomes effortless. You and your classmates can easily share and work on project materials in real time. No more passing around USB drives or emailing files back and forth. Everyone can access the same files, making teamwork smoother and more efficient.
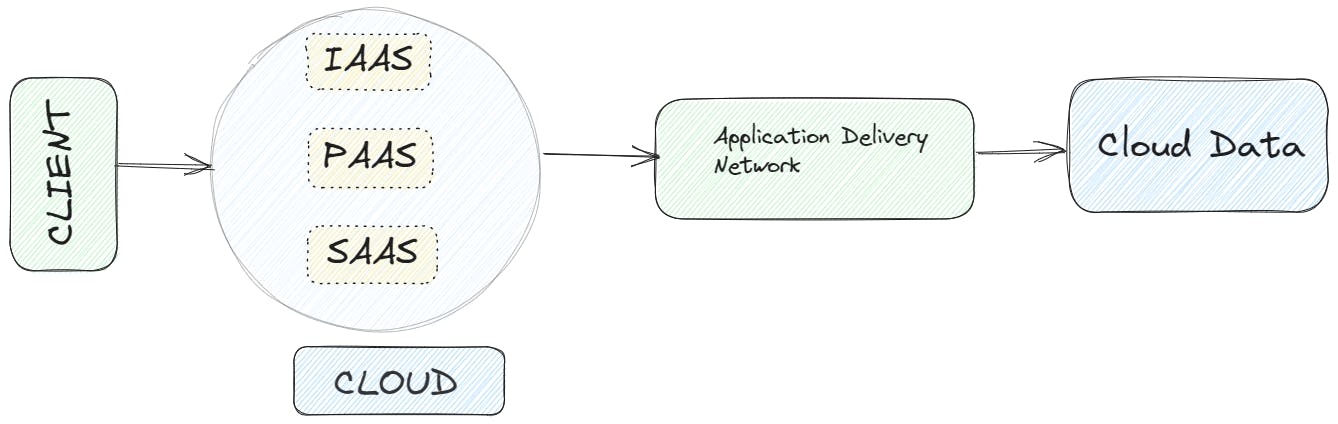
The beauty of the cloud is its scalability. As your project progresses and gains attention, you can easily expand your resources. Like adding extra space to your virtual backpack, the cloud allows you to handle increased traffic and demands without worrying about storage limitations. Cloud computing empowers you to work together seamlessly, safeguard your work, and adapt to changing project requirements.
MTBF (Mean Time Between Failures)
It is a metric used to measure the reliability of a system or component.
MTBF is a term used to estimate how long a system or component can function without experiencing a failure. It indicates how reliable and stable a device or system is. The higher the MTBF value, the longer the expected time between failures.
Imagine you have a computer or any other electronic device. MTBF tells you on average how long you can expect the device to work without encountering a failure. For example, if a computer has an MTBF of 10,000 hours, it means that, on average, it should run for approximately 10,000 hours before experiencing any issues.
MTBF is calculated by analyzing the historical data of failures in similar devices or systems. It takes into account factors such as component quality, design, and environmental conditions. Manufacturers often perform extensive testing and analysis to determine the MTBF value of their products.
MTBF is an important metric because it helps users and manufacturers understand the reliability and durability of a device or system. It can be used to make informed decisions about purchasing or using equipment. However, it's important to note that MTBF is an estimate based on statistical calculations and does not guarantee that a device will last exactly as long as the MTBF value suggests.
In summary, MTBF is a measure of how long a system or component is expected to function without encountering a failure. It indicates reliability and helps users assess the durability of devices or systems before making decisions.
CAPEX AND OPEX
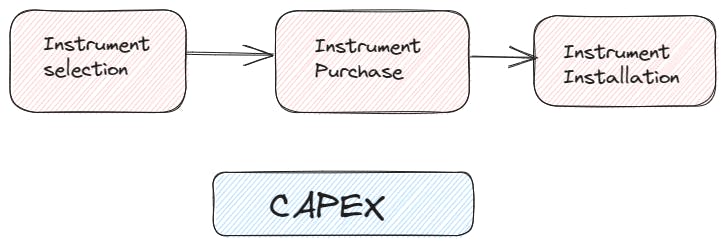
CapEx, or Capital Expenditure, refers to the money spent on acquiring or upgrading physical assets, such as buildings, equipment, or machinery. It is a one-time investment made by a company or organization to improve its infrastructure or expand its operations. CapEx expenses are typically incurred to support long-term business goals and are considered investments in the company's future growth. For example, if a manufacturing company purchases new machinery to increase production capacity, the cost of acquiring that machinery is considered a capital expenditure.
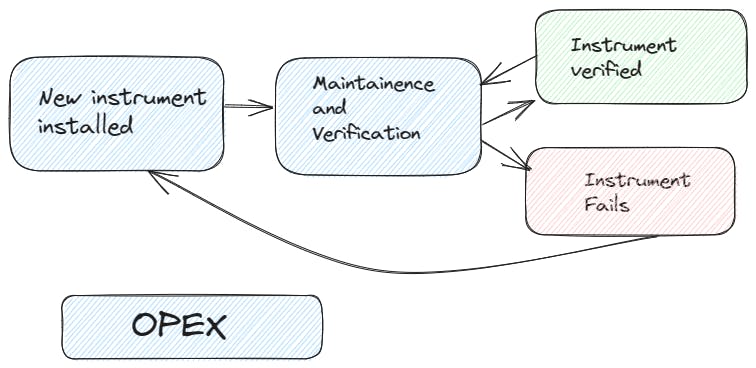
OpEx, or Operating Expenditure, refers to the day-to-day expenses incurred by a company to keep its business operations running smoothly. These expenses are recurring and necessary for the daily operation of the business. OpEx includes costs such as employee salaries, utilities, rent, maintenance, and other ongoing expenses. Unlike CapEx, OpEx is incurred regularly and does not involve long-term investments. For example, the monthly electricity bill, salaries of employees, or rent for office space are considered operating expenditures.
Let's take an example of a software company to understand the difference between CapEx and OpEx. If the company decides to build its own data center, the cost of purchasing servers, networking equipment, and constructing the facility would be considered a CapEx. It is a significant investment made upfront to create a long-term infrastructure for the company's software services.
On the other hand, the monthly salaries of software developers, the cost of cloud computing services used to run the software applications, and the electricity bill to power the office are considered OpEx. These expenses are incurred regularly to keep the business operations running smoothly.
In summary, CapEx refers to one-time investments in long-term assets or infrastructure, while OpEx refers to recurring expenses for daily operations. Understanding the difference between CapEx and OpEx helps companies make financial decisions and allocate resources effectively based on their business needs and goals.
Hypervisors and Virtualization
Virtualization in Cloud Computing: In cloud computing, virtualization is a technology that allows us to create multiple virtual computers or servers on a single physical machine. It helps in maximizing the use of resources and makes it easier to manage and share them among different users or applications. With virtualization, we can run several virtual machines or operating systems on one physical server, which leads to cost savings and better resource utilization.
Hypervisor in Cloud Computing: The hypervisor, also known as a virtual machine monitor, is software that enables the creation and management of virtual machines in cloud computing. It acts as a supervisor for these virtual machines, making sure they can run independently and securely on the same physical server. The hypervisor manages the allocation of resources like CPU, memory, and storage to the virtual machines, ensuring that each virtual machine gets what it needs without affecting others.
In summary, virtualization and the hypervisor play key roles in cloud computing by enabling the creation and management of virtual machines, leading to better resource utilization, cost savings, and flexibility in deploying applications or services.
DAY-2:
Key features of cloud computing
Availability:
Availability refers to the ability of cloud services to be consistently accessible and functioning properly. It means that users can access their applications, data, and services in the cloud whenever they require them, without experiencing significant downtime or interruptions.
Example: Imagine you are using a cloud-based email service like Gmail. The availability feature ensures that you can access your emails, compose new messages, and perform various tasks within your email account at any time. Whether you're accessing your email from a computer, smartphone, or tablet, the service remains available and functional, allowing you to send, receive, and manage your messages without disruptions.
In cloud computing, availability is achieved through various measures, such as redundant infrastructure, data replication across multiple locations, and automatic failover mechanisms. These ensure that even if one server or data center encounters an issue or goes offline, the service remains available from alternative locations or backup systems
Scalability:
Scalability refers to the ability of a cloud service or infrastructure to handle an increasing or decreasing workload effectively. It enables the system to adapt and allocate additional resources or reduce resources based on the current demand, ensuring optimal performance and responsiveness.
Example: Let's say you have developed a mobile gaming application that is hosted in the cloud. As the popularity of your game grows, more and more players start using it simultaneously. Scalability allows your game to handle this increasing number of users by dynamically allocating additional computing resources, such as servers and processing power, to support the higher workload. This ensures that all players can enjoy a smooth gaming experience without lag or delays.
In cloud computing, there are two types of scalability: horizontal scalability and vertical scalability.
Horizontal scalability, also known as scale-out, involves adding more instances of resources, such as servers or virtual machines, to distribute the workload. It allows the system to handle increased traffic or user demands by distributing the workload across multiple resources.
Vertical scalability, also known as scale-up, involves increasing the capacity of existing resources, such as adding more processing power or memory to a server. It allows the system to handle increased demands by enhancing the capabilities of individual resources.
Cloud computing platforms provide tools and mechanisms to enable scalable deployments. These platforms automatically monitor the system's performance and scale resources up or down based on predefined rules or thresholds. This flexibility ensures that applications and services can accommodate fluctuations in demand, avoiding performance bottlenecks during peak periods and optimizing resource utilization during off-peak times.
Elasticity
Elasticity is a feature of cloud computing that allows resources to automatically and dynamically scale up or down based on the current workload. It enables the system to adapt to changing demands in real-time, ensuring that the right amount of resources is allocated at any given moment.
Example: Imagine you are running an online shopping website. During holiday seasons or special sales events, there is a sudden surge in traffic as more customers visit your website to make purchases. Elasticity allows your website to automatically scale up by allocating additional servers and resources to handle the increased traffic. This ensures that your website remains responsive and accessible to all customers, even during peak periods. Once the rush is over, the resources can scale down automatically to avoid unnecessary costs, ensuring efficient resource utilization.
Agility:
Agility refers to the ability of cloud computing to provide quick and flexible provisioning of resources and services. It allows organizations to rapidly deploy and adapt their applications and infrastructure to meet business needs, reducing time-to-market and enabling faster innovation.
Example: Suppose you are a software developer working on a new application. With cloud computing, you can quickly provision the necessary resources, such as virtual machines, storage, and databases, to develop and test your application. If you need additional resources, you can easily scale up your infrastructure to accommodate the growing requirements. This agility allows you to respond quickly to market demands, launch new features, and make changes to your application flexibly and efficiently.
DAY-3:
Recognized Cloud Model:
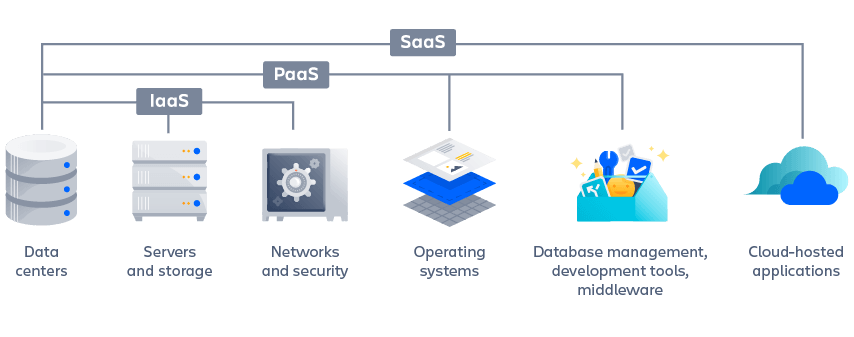
1-Infrastructure as a Service (IaaS)
IaaS is a cloud computing model where users rent virtualized hardware resources, such as servers, storage, and networking components, from a cloud provider. It provides a flexible and scalable infrastructure on which users can deploy and manage their applications and software.
Example: Imagine you are a developer creating a new web application. With IaaS, you can rent virtual servers from a cloud provider, where you have full control over the operating system, software stack, and applications. You can configure the servers according to your needs, install the required software, and manage the infrastructure. The cloud provider takes care of the underlying hardware and infrastructure maintenance, while you focus on developing and deploying your application.
2-Platform as a Service (PaaS):
PaaS is a cloud computing model where users can build, deploy, and manage applications without worrying about the underlying infrastructure. It provides a platform and runtime environment that includes tools, libraries, and services to facilitate application development and deployment.
Example: Let's say you want to develop a mobile application. With PaaS, you can leverage a cloud platform that offers development tools, databases, and middleware services. You can write your application code using the provided tools and libraries, and the platform takes care of managing the infrastructure, such as server provisioning, load balancing, and scaling. PaaS allows you to focus on developing your application logic without the need to manage the underlying infrastructure.
3-Software as a Service (SaaS):
SaaS is a cloud computing model where users access and use software applications hosted on the cloud over the internet. The applications are centrally managed and maintained by the cloud provider, and users typically access them through a web browser or dedicated client.
Example: Consider using an online productivity suite like Google Docs or Microsoft Office 365. These are SaaS offerings where you can create, edit, and collaborate on documents, spreadsheets, and presentations directly through a web browser. The software is hosted and managed by the cloud provider, eliminating the need for local installations or updates. As a user, you can access the software and your files from any device with an internet connection.
In summary, the "as-a-Service" models - IaaS, PaaS, and SaaS - provide different levels of cloud computing services. IaaS offers virtualized infrastructure resources, PaaS provides a platform and runtime environment for application development, and SaaS delivers fully managed software applications accessible over the internet. Each model offers varying levels of control, flexibility, and management responsibilities to meet the diverse needs of users and organizations.
IaaS (Infrastructure as a Service):
AWS EC2: It's like renting scalable virtual machines from Amazon's cloud. You can set up and manage your own operating systems, applications, and data.
GCP Compute Engine: Similar to AWS EC2, Google's Compute Engine provides virtual machine instances for customers to deploy and control their own infrastructure in the cloud.
Azure Virtual Machines: Microsoft's Azure VM offers resizable compute resources, allowing customers to run virtual machines and manage their applications and data.
PaaS (Platform as a Service):
Azure Functions: With Azure Functions, you can write and run event-driven functions without worrying about managing the underlying infrastructure.
AWS Lambda: AWS Lambda is a service that lets you run your code in response to events, taking care of infrastructure management automatically.
GCP App Engine: App Engine is a fully managed platform where you can deploy your code and let it automatically scale based on demand, without needing to worry about infrastructure management.
SaaS (Software as a Service):
Azure Virtual Desktop: Azure Virtual Desktop provides a virtual desktop experience in the cloud, including popular applications like Windows and Office.
AWS WorkSpaces: AWS WorkSpaces is a fully managed service that offers virtual Windows desktops on-demand, accessible from different devices.
GCP AppSheet: AppSheet is a no-code platform that allows users to create and deploy custom applications without needing coding skills.
Day-4:
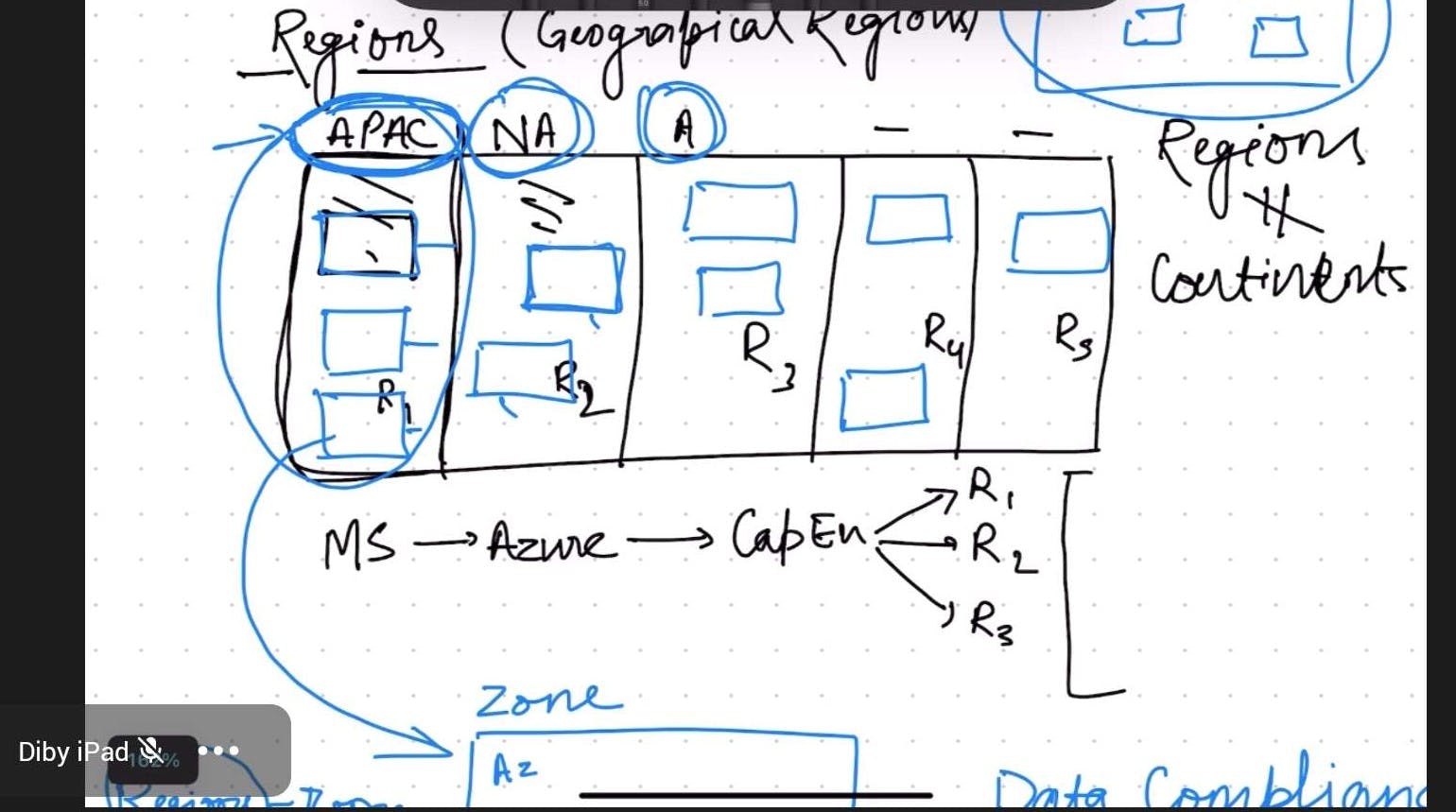
Data Centers and Availability Zones:
Data Centers in the Cloud: In cloud computing, data centers refer to the physical facilities where cloud service providers house their servers and other infrastructure. These data centers are spread across different geographic locations and are designed to provide secure and efficient environments for storing and processing data. They are equipped with robust networking, power, and cooling infrastructure to ensure the uninterrupted operation of the cloud services hosted within them.
Availability Zones in the Cloud: Availability zones are essentially isolated locations within a cloud provider's infrastructure that consist of one or more data centers. These zones are designed to provide redundancy and fault tolerance. Each availability zone is typically located in a separate geographic region and has its own power supply, networking, and cooling infrastructure. The purpose of availability zones is to ensure that if one zone experiences an issue or outage, the services hosted in other zones remain unaffected and continue to operate seamlessly.
BCDR (Business Continuity and Disaster Recovery):
BCDR (Business Continuity and Disaster Recovery) refers to the strategies and processes implemented by organizations to ensure the uninterrupted operation of critical business functions in the face of disruptions or disasters.
Imagine you have a favorite online shopping website. Now, think about what would happen if their servers suddenly crashed or if there was a natural disaster that affected their operations. BCDR is like having a backup plan to keep the website running and ensure your shopping experience isn't affected.
Business Continuity focuses on keeping essential business functions running smoothly during disruptions. For example, the online shopping website might have backup servers in a different location that automatically take over if the main servers fail. This ensures that customers can continue to browse, add items to their cart, and make purchases without any interruption.
Disaster Recovery, on the other hand, deals with recovering from major disruptions. Let's say the online shopping website's main data center gets damaged in a flood. With Disaster Recovery plans in place, they would have backups of their data stored at a separate location. They can quickly restore the data and set up temporary servers to get the website up and running again.
BCDR is crucial for businesses to minimize downtime, protect customer data, and ensure they can continue providing their services even in challenging situations. It's like having a safety net to maintain business operations and keep customers satisfied.
Latency:
Latency in cloud computing refers to the delay between sending a request and receiving a response. It can affect the speed and responsiveness of cloud-based applications. Factors like distance, network congestion, and processing time contribute to latency. Cloud service providers and developers work to minimize latency through optimized infrastructure and application design.

Azure GUI (Graphical User Interface) and CLI (Command-Line Interface)
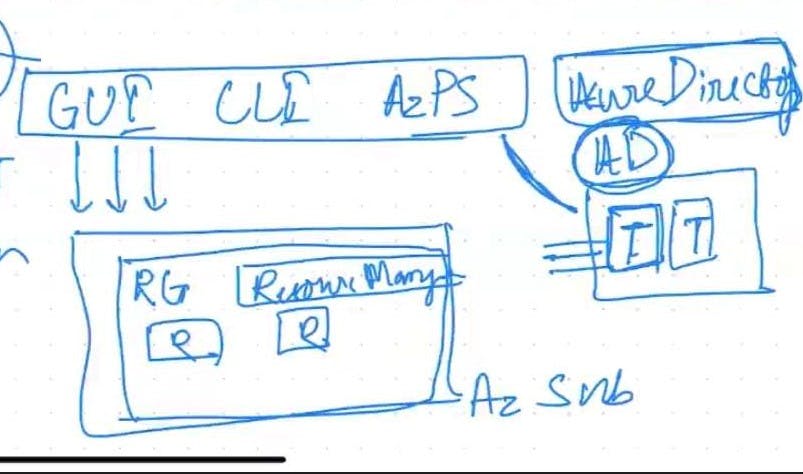
Azure GUI: Azure GUI refers to the web-based graphical interface provided by Microsoft Azure. It offers a user-friendly and visually intuitive interface for managing and deploying various Azure services. Through the Azure portal, users can access and configure resources, monitor performance, set up virtual machines, manage storage, create databases, and perform other administrative tasks. The Azure GUI simplifies the management of Azure resources by providing menus, forms, and wizards to guide users through the process.
Azure CLI: Azure CLI, on the other hand, is a command-line tool that allows users to interact with Azure services using text-based commands. It provides a command-line interface for managing Azure resources programmatically and automating various tasks. With Azure CLI, users can write scripts, execute commands, and perform administrative tasks by typing commands in a terminal or command prompt. Azure CLI provides a powerful and flexible way to manage Azure resources, and it can be used on various platforms, including Windows, macOS, and Linux.
Both Azure GUI and CLI offer different ways to interact with Azure services. The GUI provides a visual interface for managing resources, while the CLI allows for more automation and scripting capabilities through command-line commands. Users can choose the method that best suits their preferences and requirements for managing their Azure environments.
Azure Powershell
Azure PowerShell is a command-line shell and scripting language used for managing and automating tasks in Azure. With Azure PowerShell, you can write scripts to create, configure, and manage Azure resources. For example, you can automate the creation of virtual machines by writing a script that specifies the resource group, virtual machine details, and other settings, allowing you to quickly deploy and manage resources in Azure.
Azure AD (Azure Active Directory)
Azure AD is a cloud-based identity and access management service provided by Microsoft. It enables organizations to manage user accounts, control access to resources, and secure their applications and data in the Azure cloud environment.
Imagine you have a school with many students, teachers, and staff members. Azure AD is like a digital ID card system for your school. It helps manage who can access different resources and keeps everything secure.
With Azure AD, each student, teacher, and staff member gets a unique digital identity. This identity allows them to access specific online resources, such as school email, online learning platforms, or shared documents. Just like how you need your student ID card to enter the library, Azure AD ensures that only authorized people can access certain digital resources.
Azure AD also allows you to set up rules and permissions. For example, you can define that only teachers can access the grading system, or only students can access the school's online discussion forum. This way, the right people have access to the right resources, ensuring privacy and security.
Additionally, Azure AD supports single sign-on (SSO), which means you only need to log in once to access multiple applications. It's like having one key that opens many doors. This saves time and makes it easier for students and teachers to access different online tools without remembering multiple usernames and passwords.
In summary, Azure AD is a cloud-based service that manages digital identities, controls access to resources, and ensures security in the school's online environment. It simplifies access to various online tools and keeps sensitive information protected.
DAY-5:
Interactive session!
DAY-6:
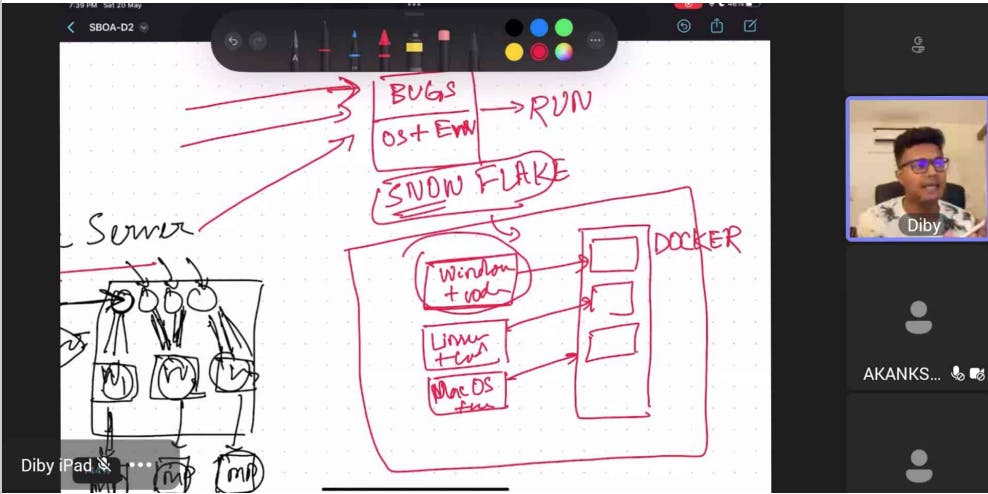
SnowFlake Server:
Snowflake servers, also known as traditional servers, refer to a traditional approach where a single physical server is responsible for hosting and running multiple applications and services. Here's a simplified explanation with an example for better understanding:
Imagine you have a computer at home, and you use it for different purposes like browsing the internet, playing games, and doing schoolwork. In this case, your computer is like a snowflake server. It hosts and runs various applications and services all on a single machine.
Now, let's say you encounter a problem with one of the applications on your computer. For instance, a game crashes and stops working. Since all the applications are running on the same machine, this issue with the game can potentially impact the performance of other applications as well. You might have to restart your entire computer to fix the problem, which can be inconvenient.
Serverless Computing on Azure:
Serverless computing on Azure refers to a cloud computing model where developers can build and run applications without the need to manage or provision servers. Azure provides a serverless computing platform called Azure Functions, which allows developers to focus on writing code for specific functions or tasks without worrying about the underlying infrastructure.
Imagine you want to create a web application that sends you a notification whenever someone fills out a form on your website. With Azure Functions, you can write a small piece of code that handles this specific task without the need to set up and manage a server.
In the serverless model, you define a function that triggers when a specific event occurs, such as a form submission. When the event happens, Azure automatically runs your function and scales it based on the incoming workload. This means that your function will handle as many form submissions as needed without you having to worry about provisioning resources or managing the infrastructure.
Some Concepts:
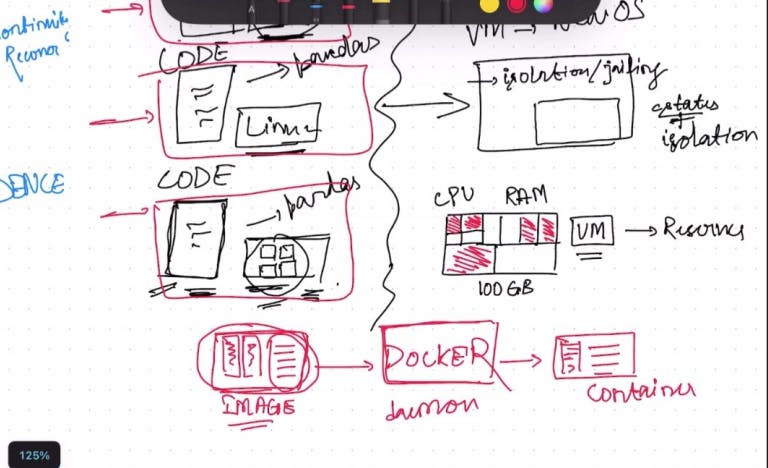
Image: In the context of containers, an image is a lightweight, standalone, and executable software package that contains everything needed to run an application, including the code, runtime environment, libraries, and dependencies. It serves as a blueprint for creating and running container instances.
Daemon: A daemon is a background process or service that runs continuously on a computer system. In the context of containerization, the daemon, also known as a container runtime, is responsible for managing and executing container images. It handles tasks such as starting, stopping, and monitoring containers, as well as managing networking and resource allocation.
Docker: Docker is a popular platform for building, deploying, and running containers. It provides tools and a runtime environment that allows developers to package their applications into container images and deploy them on any system with Docker installed. Docker simplifies the process of containerization by providing a user-friendly interface, a command-line interface (CLI), and a graphical user interface (GUI) to manage containers and images.
Container: A container is a lightweight and isolated runtime environment that encapsulates an application and its dependencies. It provides a consistent and reproducible environment, ensuring that the application runs the same way across different systems. Containers are created from container images and can be instantiated, started, stopped, and moved between different host systems using container runtimes like Docker. Containers offer benefits such as portability, scalability, and efficient resource utilization, making them popular for deploying and running applications in various computing environments.
Azure Kubernetes and Orchestrating:
Azure Kubernetes Service (AKS) is a managed container orchestration service that helps you run and scale containerized applications. For example, imagine you have a popular e-commerce website that experiences high traffic during the holiday season. With AKS, you can deploy your website as containers and let AKS manage the scaling of these containers automatically. So, when there's a surge in traffic, AKS will create additional containers to handle the load, ensuring your website stays responsive and available to customers. This way, you don't have to worry about manually managing server resources or dealing with sudden spikes in traffic. AKS takes care of it for you.
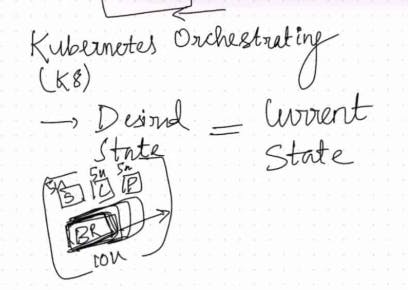
Orchestrating in the context of business continuity refers to the process of managing and coordinating various components, resources, and actions to ensure the continuous operation of critical systems and services during disruptive events. With Azure Kubernetes Service (AKS), orchestrating business continuity involves leveraging the capabilities of AKS to maintain service availability and recover from potential failures.
For example, let's say you have a web application deployed on AKS that serves as a critical component of your business operations. To ensure business continuity, you can implement strategies such as:
Replication: AKS allows you to deploy multiple instances (replicas) of your application across different nodes in the Kubernetes cluster. By distributing your application across multiple nodes, you increase redundancy and ensure that if one node fails, your application can continue running on other nodes.
Scaling: AKS provides automatic scaling capabilities, allowing you to dynamically adjust the number of replicas based on demand. During peak usage periods, AKS can automatically scale up the number of replicas to handle increased traffic. If a node becomes overwhelmed or fails, AKS can also scale up additional replicas to compensate for the loss and maintain service availability.
Load balancing: AKS includes built-in load balancing mechanisms that distribute incoming traffic evenly across the available replicas of your application. This ensures that even if one replica or node experiences issues, the load balancer redirects traffic to other healthy replicas, preventing service disruptions.
Monitoring and self-healing: AKS integrates with Azure monitoring services, enabling you to monitor the health and performance of your application. With the help of monitoring data, you can set up automated alerts and triggers to detect and respond to potential issues. AKS can initiate self-healing actions, such as restarting failed containers or scaling up replicas, to recover from failures and maintain service continuity.
Day-7:
Interactive Session!