


Day-1:
How an AI learns?
Just like a human baby, AI systems learn through a process called machine learning. Imagine we want to teach an AI system to recognize different types of animals.
Data Collection: First, we gather a large dataset of images that contain different animals, such as cats, dogs, and birds. These images are labeled so that the AI system knows which animal is present in each picture.
Training Phase: During the training phase, we show the AI system thousands or even millions of these labeled images. The AI system analyzes the images and looks for patterns and features that are specific to each type of animal. It learns to associate certain visual characteristics with each animal category.
Feature Extraction: The AI system extracts features from the images, such as shapes, colors, textures, and patterns. It uses these features to create a mathematical model that represents the learned knowledge about different animals.
Prediction: Once the training is complete, we can test the AI system's learning by giving it new, unseen images of animals. The system analyzes the features of these images and compares them to the patterns it learned during training. Based on the similarities it detects, the AI system predicts the type of animal present in the image.
Refinement: If the AI system makes incorrect predictions, we provide feedback and adjust its parameters or update its training data to improve its accuracy. This iterative process helps the AI system refine its understanding and become more accurate over time.
Just like a human baby learning to differentiate between animals by observing and associating patterns, an AI system learns by analyzing large amounts of data and recognizing patterns within it. The more data it sees and the more accurate the feedback it receives, the better it becomes at making predictions.
AI's Decision making power!
AI decision-making power involves the interplay of biases, weights, and resolution. Let's explain this using an example of a self-driving car making decisions on the road.
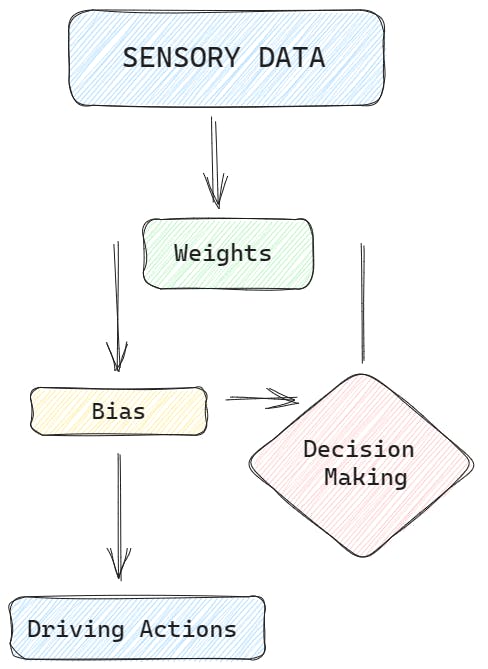
- Biases: Biases in AI decision-making can be thought of as predetermined preferences or inclinations that guide the car's behavior. For example, the self-driving car might have a bias towards prioritizing the safety of its passengers. This bias means that the car will tend to make decisions that prioritize avoiding collisions and ensuring the well-being of the passengers.
Weights: In the context of a self-driving car, weights represent the relative importance or influence assigned to different factors or features when making decisions. These factors can include the car's speed, the presence of pedestrians or other vehicles, traffic rules, and road conditions. Each of these factors is assigned a weight that determines its significance in the decision-making process.
For instance, if the self-driving car encounters a situation where it needs to make a turn at an intersection, the weights associated with factors such as traffic signals, the presence of pedestrians, and the speed of oncoming vehicles will impact its decision. The weights can guide the car to prioritize stopping at a red light, giving way to pedestrians, and making a turn only when it is safe to do so.
- Resolution: Resolution refers to the level of detail or granularity at which the self-driving car assesses its surroundings and makes decisions. It involves processing and analyzing data from various sensors like cameras, LiDAR, and radar to build a comprehensive understanding of the environment.
For example, the car's sensors detect objects such as pedestrians, cyclists, and other vehicles. The resolution of the AI system determines how well it can recognize and distinguish these objects, enabling the car to make accurate decisions based on their positions, velocities, and potential risks.
The combination of biases, weights, and resolution allows the self-driving car's AI system to navigate the roads safely. It ensures that the car prioritizes certain objectives, assigns appropriate importance to different factors, and analyzes the environment with sufficient detail.
UCF
User collaborative filtering (UCF) is a technique used in recommendation systems to provide personalized recommendations to users based on their similarities with other users. It analyzes the behavior and preferences of multiple users to identify patterns and make predictions about a user's interests.

Through UCF, YouTube strives to offer a personalized video experience to its users. By leveraging the behavior and preferences of similar users, YouTube's recommendation system suggests content that aligns with individual interests, thereby enhancing user engagement and satisfaction.
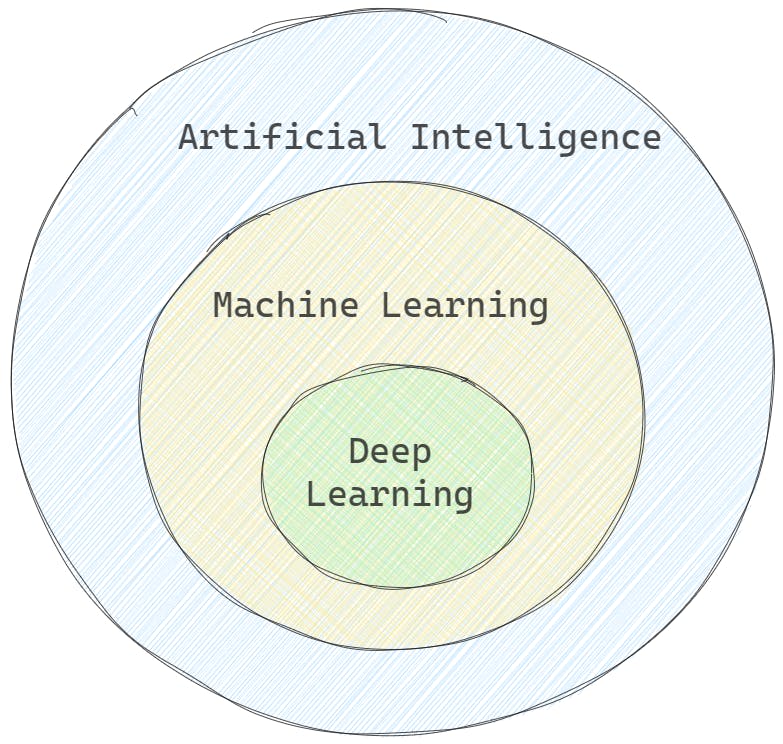
Machine Learning
Machine learning is a branch of AI that enables computers to learn from data without explicit programming. It involves training models to make predictions or decisions.
For example, in spam email detection, a machine learning model is trained using labeled data (spam and non-spam emails). The model learns patterns and relationships between features (words, email length, etc.) and labels (spam or non-spam). Once trained, the model can classify new emails as spam or non-spam based on the learned patterns.
Machine Learning Datasets
Machine learning datasets are collections of data that are used to train and evaluate machine learning models.
1-COCO Dataset
The COCO (Common Objects in Context) dataset is a widely used benchmark dataset in the field of computer vision and object detection. It is designed to facilitate the research and evaluation of algorithms for tasks like object recognition, segmentation, and captioning.
The COCO dataset consists of images that depict complex scenes with various objects in their natural context. It covers a wide range of object categories, such as people, animals, vehicles, and everyday objects. The dataset contains over 200,000 images, each annotated with object-level labels, object segmentations, and captions.
The annotations in the COCO dataset provide detailed information about the objects present in the images. Each object is labeled with its category (e.g., person, dog, car) and is outlined with pixel-level segmentation masks. Additionally, the dataset includes annotations for key points (e.g., human pose estimation) and image captions, providing rich contextual information.
2-EGOHands Dataset
The EgoHands dataset contains 48 Google Glass videos of complex, first-person interactions between two people. The main intention of this dataset is to enable better, data-driven approaches to understanding hands in first-person computer vision. The dataset provides pixel-level annotations for hand regions, including bounding boxes or polygons, indicating the spatial extent of the hands in each frame.
Machine Learning Algorithms
1-Supervised Machine Learning
Supervised learning is a machine learning approach where the model learns from labeled examples. The dataset consists of input data and corresponding target labels. The goal is for the model to learn the mapping between inputs and labels to make accurate predictions on unseen data.
In supervised learning, the algorithm learns from labeled data, where both input features and corresponding target labels are provided. The algorithm's objective is to learn the mapping between inputs and outputs to make predictions or classify new, unseen data.
1-UnSupervised Machine Learning
Supervised learning is a machine learning approach where the model learns from labeled examples. The dataset consists of input data and corresponding target labels. The goal is for the model to learn the mapping between inputs and labels to make accurate predictions on unseen data.
In unsupervised learning algorithms work with unlabeled data, meaning there are no predefined target labels. The algorithms aim to discover patterns, structures, or relationships within the data without explicit guidance or supervision.
1-Reinforcement Learning
Reinforcement learning focuses on training models to make a sequence of decisions in an environment to maximize a reward signal. The model learns through trial and error, receiving feedback in the form of rewards or penalties based on its actions.
Reinforcement learning involves an agent interacting with an environment and learning through trial and error. The agent receives feedback in the form of rewards or penalties based on its actions. The objective is to maximize cumulative rewards by discovering the best sequence of actions in a dynamic environment.
Time Series Analysis Model
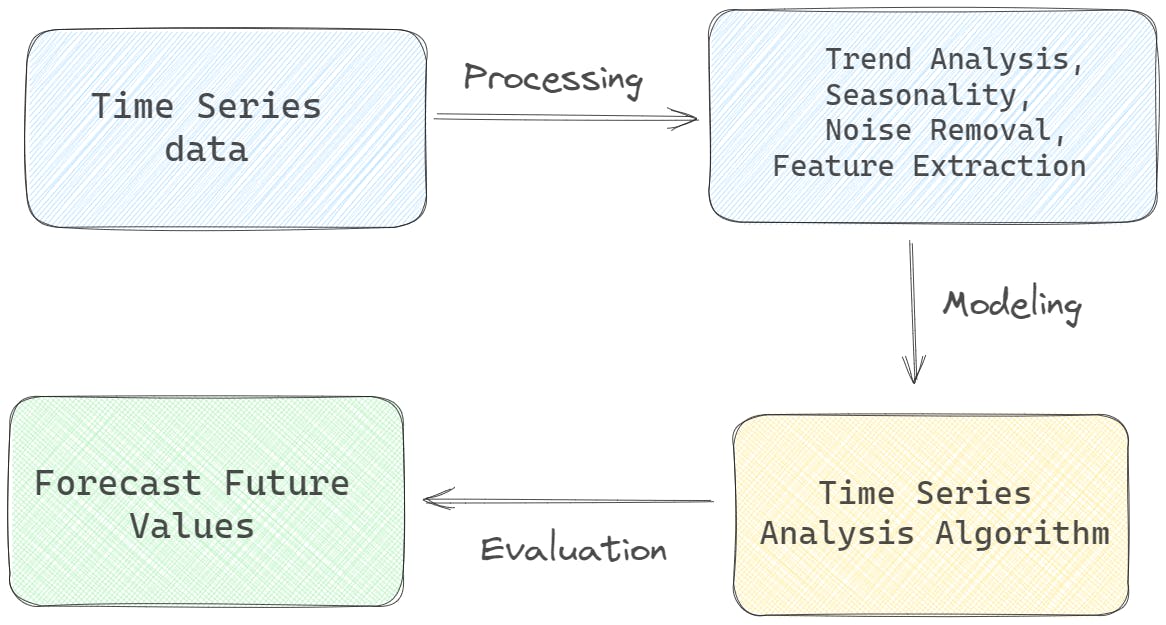
Time series analysis models are statistical and machine learning techniques used to analyze and forecast data that changes over time. Time series data consists of observations taken at regular intervals, such as hourly, daily, or monthly, and can include various types of data like stock prices, temperature readings, or sales data.
Ground Truth
In machine learning, "ground truth" refers to the accurate and reliable labeling or annotation of data used for training or evaluation purposes. It represents the true and correct values or labels associated with the input data.
Ground truth plays a critical role in supervised learning, where models are trained using labeled data to learn patterns and make predictions. The labeled data serves as the ground truth, providing the correct answers or target values for the given inputs. The model learns from this ground truth to make accurate predictions on unseen data.
For example, in an image classification task, the ground truth would consist of the correct labels assigned to each image in the training dataset. The model is trained using these labeled images as ground truth, allowing it to learn the mapping between image features and their corresponding labels.